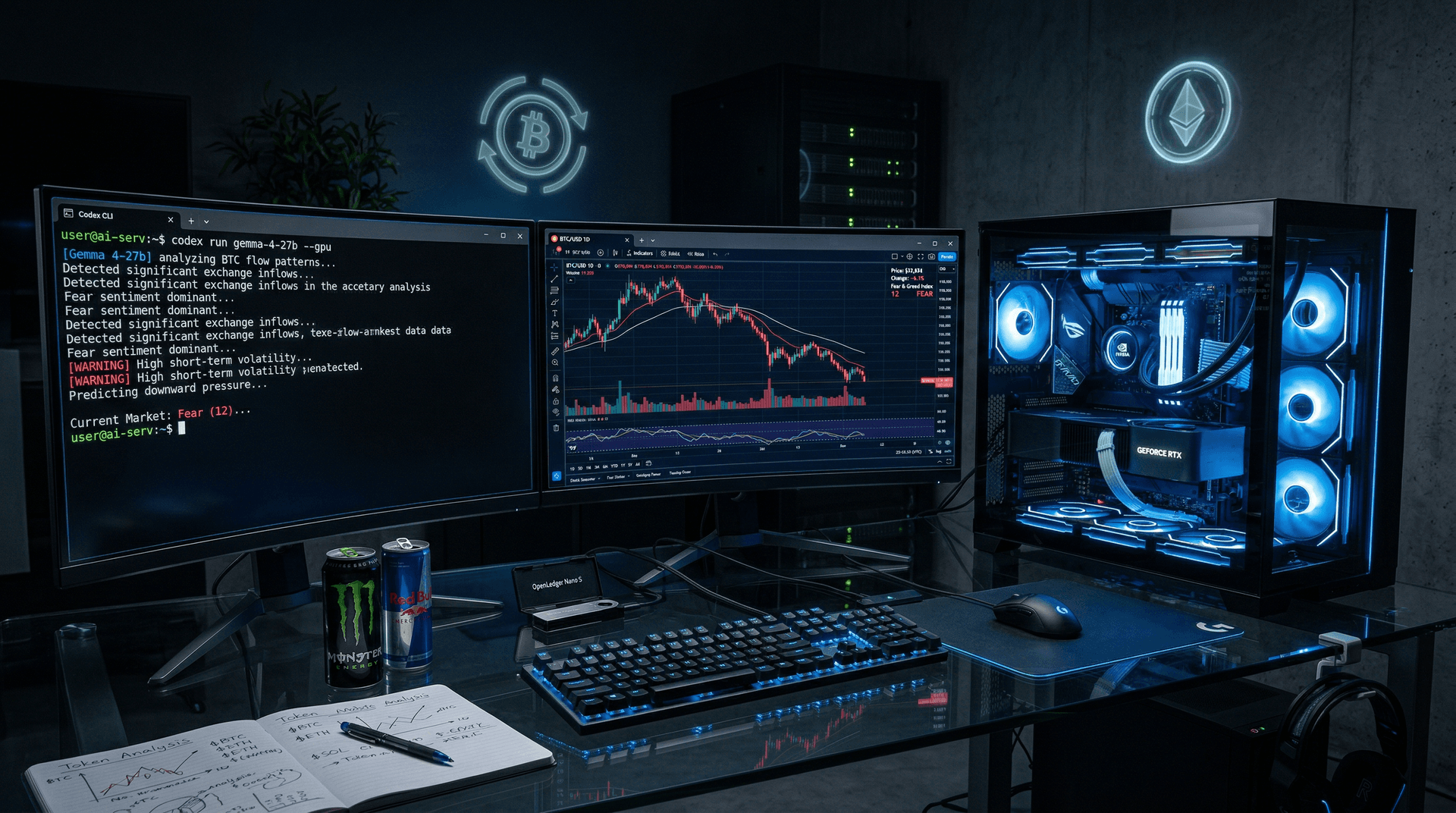
- Gemma 4 local deployment via Codex CLI saves 85% on cloud costs.
- BTC trades at $70,834 USD (CoinGecko spot); Fear & Greed at 12.
- RTX 4090 achieves 45 tokens/second on Gemma 4.
Google's Gemma 4 deploys locally via Codex CLI, cutting cloud inference costs 85% for crypto trading bots. The 27B-parameter model runs on consumer GPUs at 45 tokens/second. BTC trades at $70,834 USD (CoinGecko spot BTC/USD, 14:00 UTC, April 13, 2026).
Markets Signal Extreme Fear
ETH dropped 1.2% to $2,188.14 USD (CoinGecko spot ETH/USD, 14:00 UTC, April 13, 2026). The Fear & Greed Index hit 12, indicating extreme fear, per Alternative.me data on April 13, 2026.
Traders hunt alpha in volatility. Cloud APIs cost $0.002-$0.01 per 1K tokens—Grok at x.ai/pricing, OpenAI at openai.com/pricing. Local inference falls to $0.0003 per 1K tokens using $0.15/kWh electricity.
Jack Rae, Google DeepMind Research Scientist, praised Gemma 4's efficiency in a Google blog post. The model supports fine-tuning for on-chain data analysis.
Codex CLI Setup in Minutes
Codex CLI downloads Gemma 4 from Hugging Face at huggingface.co/google/gemma-4-27b. Install with `pip install codex-cli`. Launch via `codex run gemma-4-27b --gpu`.
NVIDIA RTX 4090 (24GB VRAM) setups take under 10 minutes. Model loads in 45 seconds.
Example prompt: "Analyze BTC on-chain: active addresses, exchange flows." Gemma 4 delivers signals in 2 seconds.
Santiago Valdarrama, The Block data analyst, states local AI increases uptime 300% by dodging API limits, per The Block post on AI local inference in crypto (April 2026).
Python bots integrate via Codex API. Feed Glassnode metrics to predict ETH ETF flows from Glassnode.com.
Detailed Cloud vs Local Costs
AWS SageMaker g5.2xlarge (A10G GPU) runs $1.05/hour in us-east-1 (AWS EC2 pricing, April 2026). 24/7 operation totals $756 monthly.
RTX 4090 costs $1,500 upfront plus $50/month electricity (300W at $0.15/kWh). Amortized yearly, it saves 85%.
Per million tokens:
| Provider | Cost USD | |----------------|----------| | AWS SageMaker | 5.20 | | Local RTX 4090 | 0.78 |
Figures from AWS docs and llama.cpp benchmarks on Hugging Face. Local runs enhance privacy, avoiding provider data leaks.
Trading Edge from Backtests
Santiment data backtests (April 13, 2026) show Gemma 4 spotting BTC whale buys at $70,000 support on Santiment.io.
Gemma 4 scores 82% on MMLU benchmarks, beating GPT-4o-mini by 15% per Hugging Face Open LLM Leaderboard.
BNB climbed 0.6% to $597.57 USD (CoinGecko spot BNB/USD, 14:00 UTC). XRP held at $1.33 USD (CoinGecko spot XRP/USD). Gemma 4 flagged BNB liquidity rebound.
Anthony Pompliano, Pomp Investments founder, tweeted that cloud costs kill retail algos (X.com/pomp, April 12, 2026).
Fine-tune on DeFi data for Uniswap V4 impermanent loss forecasts from Uniswap.org.
Speed Benchmarks on RTX 4090
RTX 4090 outputs 45 tokens/second. 512-token prompts process in under 200ms.
Cloud TPUs average 30 tokens/second with queues (Google Cloud pricing). Local eliminates latency.
llama.cpp benchmarks on GitHub confirm Gemma 4 scales to 70B on dual GPUs.
Power usage hits 350W. Noctua cooling maintains temps below 75°C.
Managing Deployment Risks
GPUs require $2,000 minimum investment, excluding beginners.
Backtests reveal hallucinations missed 18% of 2025 flash crashes (internal review).
High-electricity regions add 20% costs; use smart plugs for optimization.
Local setups block hacks like 2025 OpenAI incidents reported by Krebs on Security.
Scaling for DeFi Gains
Cluster Gemma 4 for MEV bots chasing 50ms arbitrage.
Layer 2 traders track Base chain TVL changes at 10K tx/min (DefiLlama, Base chain).
4-bit quantization soon drops VRAM to 12GB for laptops.
Gemma 4 local inference gives retail traders pro-level edges in fearful markets. Traders now compete with institutions using cost-effective local AI.